第三步:制作爬虫,爬取网页——使用基于浏览器自动化的一个模块:selenium模块,便捷的获取晋江文学小说网站中动态加载信息.项目利用热门的网络爬虫技术爬取信息,MySQL信息库持久化存储信息和最新的SpringBoot框架进行项目构建,并结合SpringMVC等热门框架技术,向读者推荐当前比较热门的小说,相似度高的同主题小说,帮组读者能够更好、更快.
网络爬虫(Web crawler),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,它们被广泛用于互联网搜索引擎或其他类似网站,可以自动采集所有其能够访问到的页面内容,以获取或更新这些网站的内容和检索.在这里我们先以笔下文学:;为准抓取一本其中的小说,例如完美世界链接是:;来达成一个简单的抓取。.
附件资源.文章浏览阅读2.1k次,点赞3次,收藏19次。C#爬虫基础 检视网页写一个爬去网络小说的程序(付完整代码)一,抓包工具的使用(以Fiddler为例)最常见的抓包工具就是Fiddler 下面是下载地址链接:https://pan.baidu.com/s/1JgBqao4-dqqtdqYkZ8s1Gw提取码:skj2打开Fiddler之后 在网页上打开网站就会在Fiddler上显示各种参数二,检视网页请求内容(以
本文介绍了如何使用SpringBoot构建JavaWeb使用,结合Python爬虫进行小说网站的信息获取和清洗.通过信息检视,系统能为网络小说作者提供流行类型、适合发布平台及篇幅建议.Java毕业设计 基于Springboot+Python爬虫创业公司死亡大信息可视化检视系统源码+部署文档+全部信息资料高分项目.
根据观察每一页的页面的网址变化 由于我们需要爬取40页的信息网络.检视完结小说以及未完结小说的占比.1.爬取网站信息 网站:https://www.hongxiu.com/.
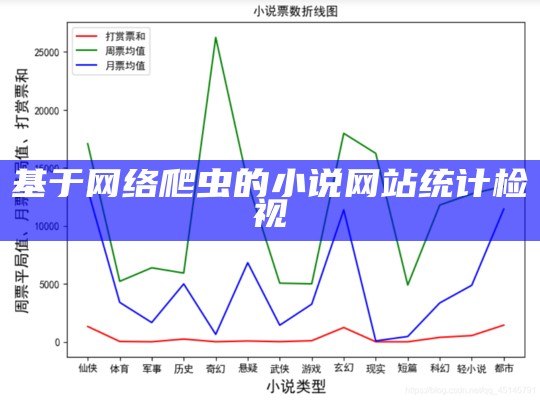
三、网络爬虫程序步骤 2.2.抓取小说网站,抓取一系列小说的篇名、作者、出版单位(或首发网站)、出版时间(或网上发布时间)、内容简介、小说封面图画、价格、读者评论或评分等多项信息,并将上述信息组织成表格形式(可以是csv、js.另外,还可以深度抓取某部小说的多个章节或全部章节进行分词和词频统计。.
基于Python的网络爬虫爬取天气信息可视化检视.zip.一、小说信息的获取(含有csv文件和MySQL的写入方法)二、信息的检视与可视化2.1、Python读取信息表时,有时候会发生一个很顽固的错误2.2、查看表的统计信息2.3、可视化图检视一、小说信息的获取(含有csv文件和MySQL的.
本系统通过Python的Scrapy-redis框架编写分布式爬虫程序,由Redis信息库作为共享的调度器和去重器,自动从豆瓣网站抓取小说相关信息,包括书名、作者、评分、评论数量、评论内容等信息,并将这些信息存入MySQL信息中,利用D.国内对于网络爬虫和信息可视化的试验起步较晚,但发展迅速REF_Ref164340522\r\h[5].
这个系统通过Python爬虫技术从小说网站上采集信息,并使用可视化技术展示信息,适合进行网络信息检视和可视化展示。.基于python网络爬虫的小说网信息采集检视与可视化项目源码(课程设计).zip.另外,还可以深度抓取某部小说的多个章节或全部章节进行分词和词频统计。.
_kaic#源码 #毕业设计 #计算机-开心V(kaic_kaic)于2024-12-17发布在今日头条,来今日头条,看见更大的世界! 推荐郑州 视频财经科技热点国际更多 军事体育娱乐历史美食直播旅游懂车帝基于Python爬虫的网络小说信息检视系统(文档+源码)_kaic#源码 #毕业设计 #计算机 播放0发布于2024-12-17 21:24 下载今日头条APP扫码下载今日头条 开心V(kaic_kaic)粉丝0关注扫码下载今日头条APP 看最新、最热资讯内容 推荐视频 01:14 联想 拯救者R9000P。为什么自营下架了?套路懂吗? #联想拯救者7328播放 直男H哥的电脑课01: