网页扒取工具,主要功能:能够将你喜欢的网页原封不动的全部获取到你的本地.weixin_63543108的博客04-182495.很好用的一个扒网站页面工具,成功率不是100%,但是大部分网站还是可以的,分享给经常扒网页的同行。.
byby0325_的博客12-291932.-r 递归下载,下载指定网页某一目录下(包括子目录)的所有文件.选择本地保存网站源文件的路径后,点击保存.
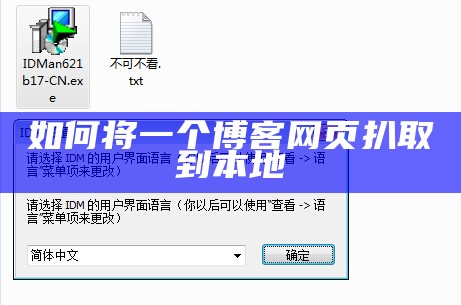
这几天一直在学用python爬网页 ,现在是用urllib2,cookie等模块获取了csdn的博客源码,然后我们进行打算把所有博客都保存到本地;这就涉及到了解析html,由于对正则的理解不太深.我需要做一个程序,可以自动打开某个网站,抓取指定位置的文字并保存到本地的文本文件中,然后我们进行自动点击下方的按钮.
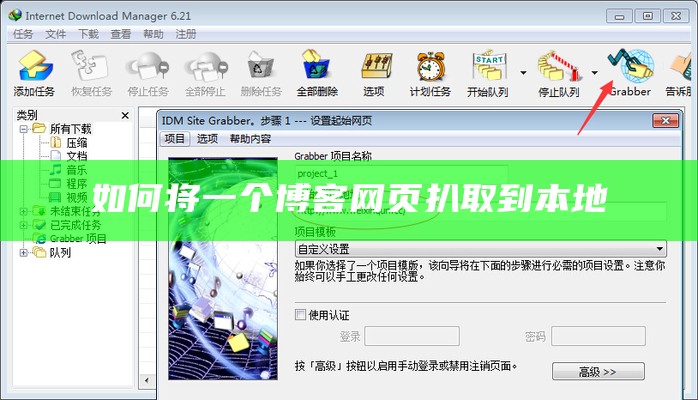
很好用的一个扒网站页面工具,成功率不是100%,但是大部分网站还是可以的,分享给经常扒网页的同行。.(图片,附件都可以下载下来哦) 我这博客刚建的时候很多错误,错位,等,我就是把整个站点复制下来(170多M,用了两个小时), 然后我们进行再找到他的CSS,改一改就OK了5、选择本地保存网站源文件的路径后,点击保存.
Python爬取第一个本地网页.欢迎使用Markdown编辑器写博客本Markdown编辑器使用StackEdit修改而来,用它写博客,将会带来全新的体验哦: Markdown和扩展Markdown简洁的语法代码块高亮图片链接和图片上传 LaTex数学公式 UML序列图和流程图离线写博客导入.如何使用pyhton的第三库BeautifulSoup来解析一个网页.
举报举报weixin_34049948的博客01-122624.在线扒站源码技术是一种网页抓取或网页统计提取的方法,它主要用于获取网站的HTML、CSS、JavaScript等源代码,以便于检视、学习或者构建类似的功能.
def save_page(url): 保存页面到本地 :param url:网页地址 :return: soup = request(url) # 获取真正需要到内容 valuable_content = soup.select('.post-body')[0] html = get_html(valuable_content) #生成一个文件名 crawler name = get_path(url) write_file(name, htm.前言案发经过:最近在学习python,对爬虫非常赶兴趣。在闲鱼上翻到有一本叫作Python3网络爬虫开发实战的书,但是又不想掏钱买,所以就在网上搜索pdf版。无意间找到 如何
Python抓取聚划算商品检视页面,获取商品信息,并将信息以XML格式保存到本地的详细知识点如下: 1. 网络请求与响应解决:文章首先考虑的是介绍了使用Python标准库urllib2进行网页的请求,以及如何配置请求头(headers),.打赏举报举报weixin_34401781的博客02-191716.
在标题 qqlogin.rar_Python脚本_python登录_网页_网页登录 中,我们可以看出这是一个关于使用Python编写登录网页QQ的源码.举报举报CZ-001的博客05-231088.本文以GitHub为例,详细介绍了如何使用Python3达成目标这一过程.
标题中的 扒网站神器.zip 指的是一个包含有用于抓取网站内容工具的压缩包文件,这类工具通常被称为网站克隆器或网页爬虫.pythonlaodi的博客11-16696.