该资源提供了一个用于禁止搜索引擎抓取网站特定区域的robots.txt模板,适用于Discuz!X2系统.通过设置robots.txt文件禁止百度等搜索引擎抓取,可以避免用户隐私和敏感商业信息泄露.HTTPS协议可以加密传输到网站的信息,防止中间人攻击和信息窃听,因此保护网站内容免受恶意采集者的攻击.
而搜索引擎收录网站页面是需要通过蜘蛛访问网站,并对页面内容进行抓取.所以通常情况下,想要阻止搜索引擎的收录就需要限制、屏蔽蜘蛛的访问与抓取.一般情况下,网站建立并运营之后总是希望被搜索引擎收录的数量越多越好.
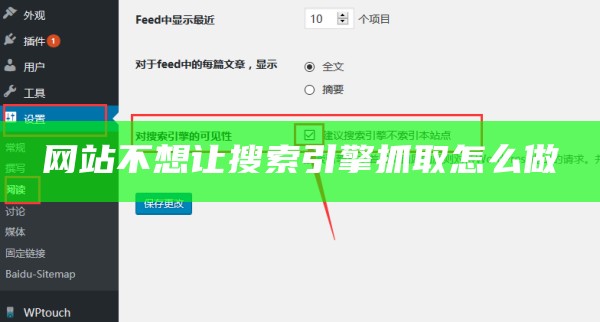
三、利用服务器中的 网站安全狗 设置静止搜索引擎抓取.通过以上的步骤就可以让搜索引擎不抓取网站的方式.
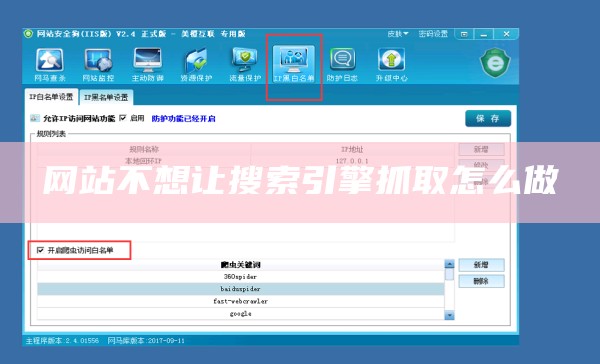
网站想要取消限制搜索引擎抓取可以直接在网站后台进行设置,通过上传robots文件或者在服务器上面利用网站安全狗软件设置静止抓取等方式.直接在网站后台进行设置时,可以登录wordpress网站后台,点击设置按钮和阅读按钮,然后我们进行找到建议搜索引擎不索引本站点前面的框框,然后我们进行勾选这个框框,然后我们进行点击保存更改即可;如果通过上传robots文件的方式,可以先在本.
在某些情况下,我们可能希望禁止搜索引擎收录或阻止网络爬虫抓取网站内容,以保护隐私、避免资源浪费或者防止敏感信息泄露.~robots.txt~ 文件是网站与网络爬虫(包括搜索引擎蜘蛛)之间的一种通信方式,用于告诉爬虫哪些页面可以抓取,哪些页面不可以抓取.
禁止搜索引擎/蜘蛛抓取的规则文件 robots.txt模板.公安备案号11010502030143京ICP备19004658号京网文〔2020〕1039-165号经营性网站备案信息北京互联网违法和不良信息举报中心家长监护网络110报警服务中国互联网举报中心Chrome商店下载账号管理规范版权与免责声明版权申诉出版物许.
给大家发一张禁止搜索引擎抓取网站的搜索判断截图:.Robots是站点与spider沟通的关键渠道,站点通过robots文件声明本网站中不想被搜索引擎收
搜索引擎蜘蛛来到站点准备抓取网页内容之前,会先访问该网站根目录下的robots.txt文件,如果不存在该文件,则搜索引擎蜘蛛默认这个网站允许其全部抓取.robots.txt是一个简单的纯文本文件(记事本文件),搜索引擎蜘蛛通过robots.txt里的内容来判断该网站是否可以全部抓取或部分抓取。.
在网站首页代码与之间,加入meta name= robots content= noarchive /代码,此标记禁止搜索引擎抓取网站并显示网页快照。.meta标签,如果不想搜索引擎建立快照的话在网页head部分加上meta name= robots content= noarchive ,不想让搜索引擎收录的话加META NAME= ROBOTS CONTENT= NOINDEX, NOFOLLOW 其中noindex属性是不收录本页,nofollow属性是不收录网页链接里的其他网.
有使用robots.txt文件、在WordPress后台设置、使用noindex标记、使用PHP函数、使用Nginx配置等多种方法。 使用robots.txt文件 你可以创建一个名为r