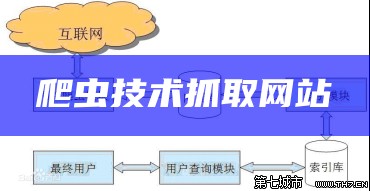
网络爬虫(Web crawler),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,它们被广泛用于互联网搜索引擎或其他类似网站,可以自动采集所有其能够访问到的页面内容,以获取或更新这些网站的内容和.传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件.
其实,许多人口中所说的爬虫(web crawler),跟另外一种功能 网页抓取 (web scraping)搞混了。.也就是说,用爬虫(或者机器人)自动替你完成网页抓取工作,才是你真正想要的。.
某些网站反感的到访,于是对爬虫一律拒绝请求.扒取别人网站统计,C#爬统计,抓取别的网站上的统计,使用在自己的网站上!.技术研发部官方博客05-122148.
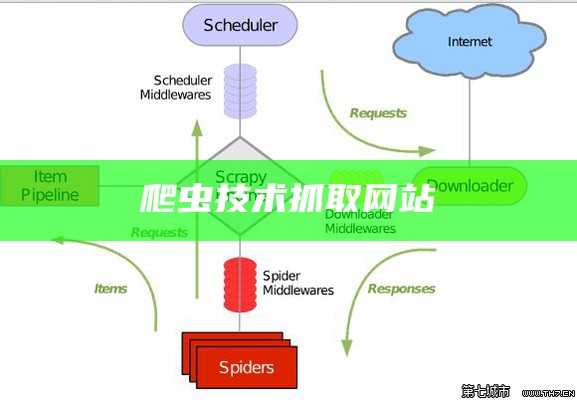
3)爬虫从待抓取 URL队列依次读取,并将URL通过DNS解析,把链接地址转换为网站服务器对应的IP地址。.尽管爬虫技术经过几十年的发展,从整体框架上已相对成熟,但随着互联网 的不断发展,也面临着一些有难题性的新困难.另外一种方法是将广度优先搜索与网页过滤技术结合使用,先用广度优先策略抓取网页,再将其中无关的网页过滤掉.
在这个实战博客中,我们将创建一个简单的Java网络爬虫,来演示如何从网页上抓取信息. 总之,这个Java项目结合Python技术的微博舆情检视系统,.
Robots协议(也叫爬虫协议、机器人协议等),全称是 网络爬虫排除标准 (Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取,例如:.针对这些情况,聚焦爬虫技术得以广泛使用。.搜索引擎和DNS解析服务商(如DNSPod等)合作,新网站域名将被迅速抓取。.
本文将深入探讨如何使用爬虫技术来抓取HTML文件,并从中提取特定统计,最后将其转换为所需格式.确切功能是,通过scrapy和Python编程对BBS网站进行抓取统计。.Python爬虫是使用Python编程语言进行网络统计抓取的一种技术.
本文将介绍一种高效的爬虫工具——Flash爬虫,它可以快速地抓取目标网站的统计,并且支援多线程、分布式等高级功能。.Flash 爬虫是一种基于 Python开发的爬虫框架,它采用了异步 IO技术和事件驱动模型,能够高效地解决大量并发请求,并且支援多种统计存储方式.如果你需要快速地抓取网站统计,那么 Flash爬虫将是你不错的选择。.
网络爬虫自动抓取,是一项令人着迷的技术.比如,在旅游行业中,有一家网站利用爬虫自动抓取各大航空公司的机票信息,并进行价格比较和推荐.网络爬
Java网络爬虫是一种用于自动化抓取互联网信息的程序,它在信息技术领域中扮演着关键角色,主要是在统计检视、搜索引擎优化和内容监测等方面.JAVA使用爬虫抓取网站网页内容的方法.Python爬虫技术的网页统计抓取与检视.pdf.