zookeeper选举机制图.全新集群选举中,编号较大的服务器更容易胜出.
选举机制1)半数机制:集群中半数以上机器存活,集群可用.2)虽然在配置文件中并没有指定但是,zookeeper工作时,是有一个节点为leader,其他则为follower,Leader是通过内部的选举机制临时产生的.假设有五台服务器组成的zookeeper集群,它们的id从1-5,与此同时它们都是最新启动的,也就是没有历史统计,在存放统计量这一点上,都是一样的.

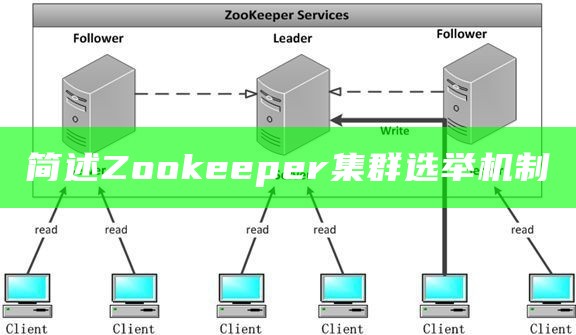
一、基本概念 1.集群机器 ID 2.事务 ID 3.Zookeeper 服务器角色 3.1 Leader 3.2 Follower 3.3 Observer 4. Zookeeper 服务器工作状态 二、选举前提条件 三、选举时机 1.服务器启动初始化的Leader选举 2.服务器运行期间的Leader选举.是指 ZXID,Zookeeper会给每个更新请求分配一个事务 ID,它是一个 64位的数字,由 Leader统一进行分配,全局唯一,不断递增,在一个节点的状态信息中可以查看到最新的事务 ID信息
它是zookeeper默认提供的选举算法,核心方法如下:确切的可以与本文上面的流程图对照。.配置多个实例共同构成一个集群对外提供服务以达到水平扩展的目的,每个服务器上的统计是相同的,每一个服务器均可以对外提供读和写的服务,这点和redis是相同的,即对客户端来讲每个服务器都是平等的。.默认的算法是FastLeaderElection,所以这篇主要检视它的选举机制。.
其选举机制是Zookeeper集群中至关关键的部分,它决定了哪个服务器成为领导者(Leader),负责解决所有的写操作和维护集群状态.zookeeper的选举机制.Zookeeper集群由多个实例组成,每个实例都拥有相同的统计,并且可以提供读写服务.
当Zookeeper集群中的一台服务器出现服务器初始化启动,或者服务器运行期间无法和Leader保持连接时,需要进入Leader选举。.Leader选举是保证分布式统计一致性的关键。.
Zookeeper集群通常由奇数台服务器组成,选举过程涉及到ZXID和MYID的比较.但是,Zookeeper工作时,是有一个节点为Leader,其他则为Follower,Leader是通过内部的选举机制临时产生的。.
1、选举过程中服务器的状态2. 选举机制3、集群启动阶段的选举4、服务运行时期的Leader选举5、当集群中的节点只剩一个时相关专栏.假设正在运行的zookeeper01、zookeeper02、zookeeper03三台服务器,当前leader是zookeeper02,若某一时刻leader挂了,此时便开始leader选举.
全新集群选举是新搭建起来的,没有统计ID和逻辑时钟的统计影响集群的选举.服务器2启动,首先考虑的是会给自己投票,然后我们进行按照这个方式,在集群中启动zookeeper服务的机器发起投票对比,这时它会与服务器1交换影响,由于服务器2的编号大,所以服务器2胜出,此时服务器1会将票投给服务器2,但此时服务器2的投票数并没有大于.
一、zookeeper集群.默认的算法是FastLeaderElection,所以这篇主要检视它的选举机制。.