目标:从一个网站的顶层开始,爬取该网站所有内链和外链,便于绘制网站地图!.以上就是构建一个能够获取网站外链并进行递归抓取的易语言爬虫所需的关键知识点.
速度更快。利用BeautifulSoup还可以有针对性的获取网页链接:Python爬虫获取网页上的链接,通过beautifulsoup的findall()方法对
想要使用ytho提取一个网页的所有连接,并不是很困难的事情,结合一些第三方模块可以方便的达成这个功能,例如:BeautifulSou 新闻网页贴吧知道经验 音乐图片视频地图百科文库悬赏令商城python怎么抓取网站所有链接 原创 | 浏览:9524 | 更新:2018-08-16 15:06 | 标签: PYTHON想要使用python提取一个网页的所有连接,并不是很困难的事情,结合一些第三方模块可以方便的达成这个功能,
可以百度LmCjl在线工具,里面就有这个抓取链接的工具.然后我们进行,使用正则表达式解析网页内容文本,找到所有的 a 标签即达成需求。.
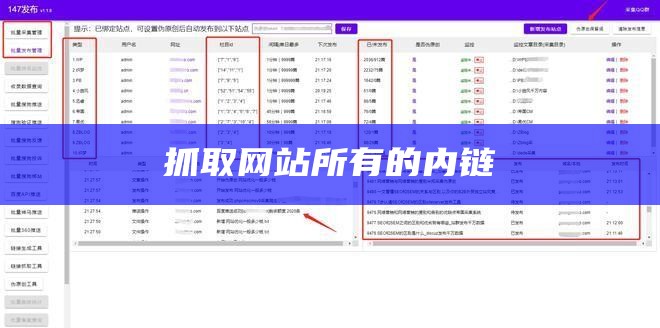
【爬虫实践】用递归获取网站的所有内链和外链.目标:从一个网站的顶层开始,爬取该网站所有内链和外链,便于绘制网站地图! 通常网站的深度有5层左右的网页,广度有10个网页,所有大部分网站的页面数量都在10的5次方,就是10万个以内,但是python递归默认限制.
省去大量手工整理时间,工具自动获取网站所有内链,方便快捷!.网页链接提取工具免费版(网站内链获取) v1.0绿色版.
3.抓取成功后,点击复制后果,即可复制全部链接,也可以移动鼠标到右边输入框,全选复制.在线批量获取网页链接的工具,可抓取网站的全站链接. 懒人推荐:智能化抓取链接主动提交百度,点击进入智能化抓取链接使用说明 1.在左边文本框输入单挑链接,然后我们进行输入抓取层数,点击抓取,就会自动根据您的链接,去爬取全站链接。 2.抓取过程中,可点击停止 3.抓取成功后,点击复制后果,即可复制全部链接,也
这样做的后果,显而易见网站降权还是会呈现在本人的头上,笔者倡议,内链一定是站在为用户和搜索引擎效劳的根底之上,主要表现如今为用户寻觅更
项目介绍代码大纲网站详情代码详情队列内链外链请求头完整代码爬取后果项目介绍.它是一个工具箱,通过解析文档为用户提供需要抓取的信息,因此简单,所以不需要多少代码就可以写出一个完整的使用程序.
网站停更了小半年,从9月10号开始又开始慢慢更新但是没有收录了(2 个月前).赞同0评论 0收藏举报评论取消血管瘤·血管瘤论坛-中国血管瘤患者之家-换医疗权2友链QQ:897834588网站地图和一个叫什么的.