利用机器学习对文本进行分类,与对数值特征进行分类最大的区别是:对文本进行分类时要先提取文本特征,相对于之前的项目来说,会有超过万个的特征属性,甚至会超过10万个。.文本特征属于非结构化的信息,一般要转换成结构化的信息才能通过机器学习算法进行文本分类.
在全球化的今天,许多企业都拥有多语种的网站来吸引和服务不同语言的用户,为了有效管理和组织这些内容,需要进行多语种文本分类,以下是详细的多语种文本分类工作流:.在文本分词后,可以提取出一些有用的特征,如词频、TFIDF值等,这些特征将用于后续的分类任务。.需要从网站上收集各种语言的文本信息,这通常通过爬虫程序来达成目标,它可以自动访问网站并提取所需的
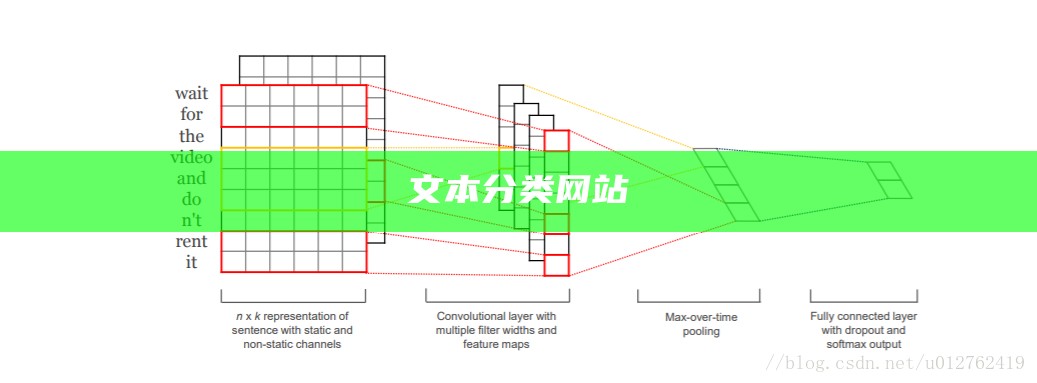
基于ELMo词向量的textCNN中文文本分类python代码. **textCNN**textCNN是一种实践于文本分类的卷积神经网络模型,由KIM在2014年提出.公安备案号11010502030143京ICP备19004658号京网文〔2020〕1039-165号经营性网站备案信息北京互联网违法和不良信息举报中心家长监护网络110报警服务中国互联网举报中心Chrome商店下载账号管理规范版权与免责声明版权申诉出版物许.
分类专栏: 文本分类文章标签: 文本分类.2016年facebook开源的一款高效词表示和文本分类工具。.
据介绍,文本分类最有用的领域目前是辨别钓鱼网站、诱导链接以及垃圾邮件过滤等。.为了利用这些信息,Facebook使用了各种各样的工具来对文本
北京联合大学毕业设计I摘要随着Web上信息的迅速扩展,各项基于Web的服务也逐渐繁荣起来,作为这些信息服务的基础和关键组成部分,Web信息采集正广泛实践于搜索引擎,站点结构调查,页面有效性调查,用户兴趣挖掘以及个性化信息
run(多标签分类/Embedding/test/sample实例).- bert,word2vec,random样例在test/目录下,注意word2vec(char or word), random-word, bert(chinese_L-12_H-768_A-12)未全部加载,需要下载 - multi_multi_class/目录下以text-cnn为例进行多标签分类实例,转化为multi-onehot标签类别,分类则取一定阀值的类 .
搜狗新闻语料文本分类实践.本文作为曾经在实验室工作的少许经验,记录当初对文本分类方面的部分实践过程.
传统的文本方法的主要流程是人工设计一些特征,从原始文档中提取特征,然后我们进行指定分类器如LR、SVM,训练模型对文章进行分类,比较经典的特征提取方法如频次法、tf-idf、互信息方法、N-Gram。.文本分类应该是自然语言应对中最普遍的一个实践,例如文章自动分类、邮件自动分类、垃圾邮件识别、用户情感分类等等,现在很多文本分类项目直接用了CNN,但这篇文章暂时只介绍LR用于
为了验证语料的有效性,我们采用五种经典的文本分类算法进行评测,即中心法[1]、最近邻[4]、Winnow[5]、贝叶斯[6]与SVMTorch[7].但手工收集上万篇文本确实比较困难,由此可见收集工作进展较慢.