大站优先策略(Larger Sites First)大站优先策略思路: 以网站为单位来选题网页关键性,对于待爬取URL队列中的网页,根据所属网站归类,如果哪个网站等待下载的页面最多,则优先下载这些链接,其本质思想倾向于优先.接下来主要说一下网络爬虫的爬取策略:.
【免费】初学者scrapy框架爬取统计不成功,出现ERROR:Spidererror.公安备案号11010502030143京ICP备19004658号京网文〔2020〕1039-165号经营性网站备案信息北京互联网违法和不良信息举报中心家长监护网络110报警服务中国互联网举报中心Chrome商店下载账号管理规范版权与免责声明版权申诉出版物许.
HTTP/2 网站爬取.最近写爬虫的时候遇到了一个用HTTP 2.0协议的网站,requests那套老经验在它身上不好用了,得专门针对HTTP 2.0进行开发。.
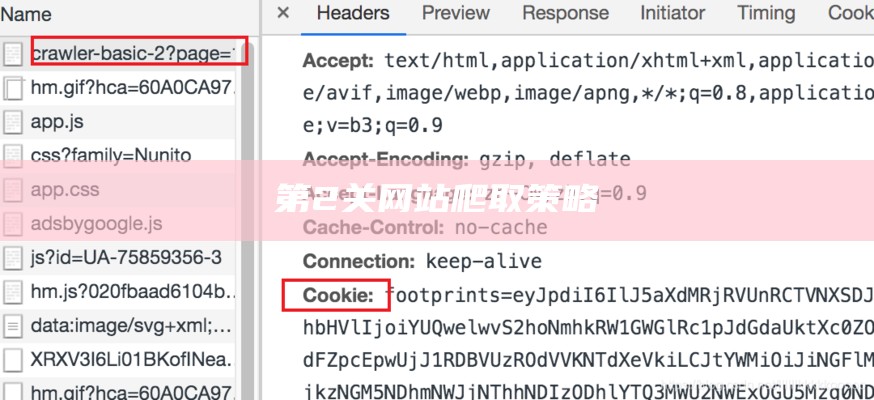
前言第1关:单网页爬取任务描述编程要求测试说明第2关:网站爬取策略编程要求测试说明第3关:爬取与反爬取任务描述编程要求测试说明第4关:爬取与反爬取进阶任务描述编程要求测试说明前言.文章目录前言第1关:单网页爬取第2关:网站爬取策略第3关:爬取与反爬取第4关:爬取与反爬取进阶相关专栏.
使用python爬虫爬取页面信息,进行解决,使用re,bs4,xpath,css等方法,用selenium自动化爬取信息并进行解决.爬虫示例网站.zip_python练习_python爬虫_usualksy_爬虫_爬虫练习网站.目录 抓取策略 宽度优先策略 非完全PageRank策略(争议很大,未必比宽度优先好.故而了解即可) OCIP策略(Online Page Importance Computation) 大站优先策略 抓取策略 最简单的一种:按照队列顺序,当前下载网页的URL地
介绍了使用哈希、BitMap、Bloom Filter记录爬取历史,并提供了实战案例——爬取蚂蜂窝城市游记。.公安备案号11010502030143京ICP备19004658号京网文〔2020〕1039-165号经营性网站备案信息北京互联网违法和不良信息举报中心家长监护网络110报警服务中国互联网举报中心Chrome商店下载账号管理规范版权与免责声明版权申诉出版物许.
第2关:爬取网站实训图片并下载.【C语言】常用字符串函数大盘点1247.NET 发布策略详解ZZNUOJ(C/C++)基础练习1041——1050(详解版)63.NET开发中的实体关系与种子统计ZZNUOJ(C/C++)基础练习1021——1030(详解版)648最新文章.本文档详细介绍了使用Scrapy爬虫框架爬取网站图片并下载到本地的过程.
Python源码自动办公-28 Python爬虫爬取网站的指定文章.rar. 3. 设置请求参数:根据新浪博客的反爬策略,可能需要设置User-Agent.标题中的 python爬取第一PPT爬虫PPT 指的是使用Python编程语言编写网络爬虫程序,目标是抓取特定网站上的PPT资源.
第2关:小说网站玄幻分类第一页小说爬取.对于反爬策略,可以通过设置代理、随机化User-Agent、模拟登录等方式应对.
他们的统计是斯坦福大学网站中的18万个页面,使用不同的策略分别模仿抓取.多可网络爬虫是其中的一个特定完成,专注于提供智能且高效的爬取对策.Baeza-Yates等人在从.gr域名和.cl域名子网站上获取的300万个页面上模拟实验,比较若干个抓取策略。.