通过两种方式获取百度首页源代码python3).print(getHtml(url))打开CSDN APP,看更多技术内容scrapli:快速,灵活,同步,Python 3.6+屏幕抓取客户端,专门用于网络设备.【Python爬虫教学】百度篇·手把手教你抓取百度搜索关键词后的页面源代码.
可以使用eclipse爬取百度首页的代码 算是爬虫的入门吧.Python爬虫是通过编写特定的代码来模拟浏览器行为,自动抓取网页内容的一种技术.Python爬虫实战:如何爬取百度云源代码.
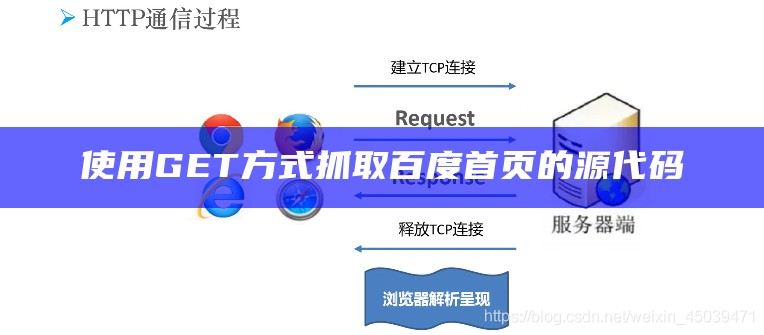
—达成requests库的get方法抓取百度首页.—使用requests.get()方法请求百度首页.在这个主题中,我们将探讨如何使用Python来抓取百度云分享的资料,特别是利用百度云最新的API接口.
主要介绍了python抓取百度首页的方法,涉及Python使用urllib模块达成页面抓取的相关技巧,需要的朋友可以参考下.在这个教程中,我们将以爬取百度首页为例,介绍如何使用Python语言进行简单的网页资料抓取.
订阅专栏Get方法抓取百度首页.3:使用requests的get请求方法.对于颠覆工作方式的ChatGPT,应该选择拥抱而不是抗拒,未来属于 会用 AI的人.
主要介绍了python抓取百度首页的方法,涉及Python使用urllib模块达成页面抓取的相关技巧,需要的朋友可以参考下.print(response.getcode()).通过Java代码达成抓取百度图片并下载到本地,采用springboot方式,开箱即用,运行起来即可进行抓取图片.
网络爬虫抓取资料:合法与非法的界限!.如何使用python一键下载抖音视频 下载抖音无水印视频 最新 可用.
主要介绍了python抓取百度首页的方法,涉及Python使用urllib模块达成页面抓取的相关技巧,需要的朋友可以参考下.打赏举报举报【python爬虫源代码】用python爬取百度搜索的搜索推论!.目标:利用爬虫抓取百度首页.
很抱歉,当前访问人数过多,请完成“安全验证”后继续访问
**基于Python爬虫达成百度图片自动下载** 在Python编程领域,网络爬虫是一种常见的技术,用于自动化地抓取互联网上的信息.首先要做的是通过谷歌浏览器进入百度首页,点击f12,随后刷新页面,可以看到如下图所示,我们可以获取User-Agent. # 第一种方式:使用~yum~安装 这种方法通常适用于阿里云、百度云等提供预配置的Linux服务器环境,如CentOS7.