爬取的微博内容既有个人观点的微博内容,也有中央地方媒体的宏观报道,而宏观报道对于检视民众情感并无用处,所以在信息解决中将媒体发布的内容剔除.今天继续使用新版微博 一、网页检视依旧是女神迪丽热巴ߘ 找到热巴的主页,依旧先打开开发者模式,随后刷新网页.通过登录之后再爬取,被封禁的几率小很多,但是如果用一个账号频繁请求页面,那么就可能会被封号.
爬取一个用户的所有微博.另外,可能还需要模拟登录,解决验证码,以获取个人或特定用户的微博信息.MySQL修改root密码的4种方法119922Pandas 获取列名95388python pandas消除空值和空格以及 Nan信息替换71638latex中,如何定义definition 和theorem65431wireshark过滤MAC地址/物理地址64752分类专栏.
爬取个人微博主页前10条微博的.python爬取微博网页信息.
由于此爬取微博主页或者较为困难,所以我们爬取,这是一个落后的塞班年代的网页,没有混淆等等一系列新技术,用户动态等从html里面就可以获取,爬取相对来说比较简单。.我们这次的目标是爬取微博个人用户的资料信息和动态信息并保存在mysql信息库中。.Python爬虫实战:如何爬取和检视新浪微博信息.
我们这次的目标是爬取微博个人用户的资料信息和动态信息并保存在 mysql 信息库中。.由于此微博对访客进行了限制,所以请求里面没有 cookies 的话动态无法抓取完全。.有了前面的铺垫,爬取用户资料便比较容易完成了。.
在本文中,我们将深入探讨如何使用Python爬虫技术来爬取微博信息,检视情感倾向,以及将推论以可视化的方式展示.通过个人微博/官方微博ID,获取一定时间段以内该用户所转发的所有内容并按一定格式存储到本地。.根据微博用户名搜索爬取该用户userId并返回.
依据目标用户微博个人资料,制作目标用户个人电子名片 可视化目标用户日、月、年度微博点赞数、转发数 依据目标用户原创微博所@用户,可视化用户好友关系图 设置评论数阈值,爬取目标用户热门微博.python新浪微博爬虫,爬取微博和用户信息(源码).另外,可能还需要模拟登录,解决验证码,以获取个人或特定用户的微博信息.
新浪微博信息的爬取主要有两种方法,当然也可以说博主只知道这两种方法,一种是使用新浪API获取,另一种是结合正则直接爬取页面信息.本文是信息爬取的第一部分,以Python完成新浪用户个人信息的爬取,其余篇章将在后续博文中陆续给出。.此前在模拟新浪微博登录:从原理检视到完成这篇博文中讲解了如何登陆新浪微博,虽然模拟登录看似比较复杂,但将其过程理解透彻之后,
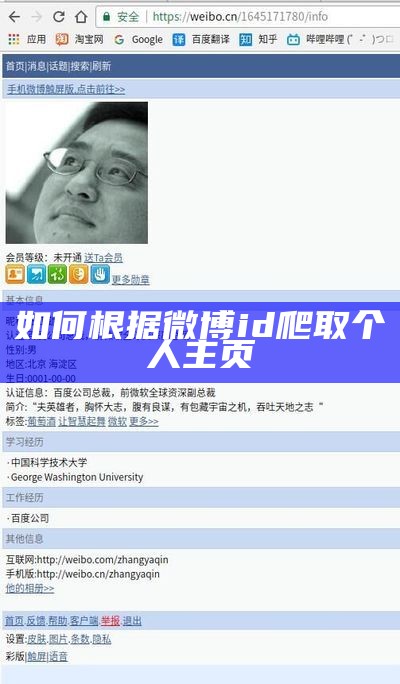
随后在网址后面加入每个人的id就可以识别到这个人的微博了,这里拿沈腾的微博作为列子.评论内容在另外的一个请求中,也是通过一个值来进行分页爬取.但是第一个信息并不是我们想要的信息,应该是每个人微博资料.
微博OAuth2.0协议是微博平台提供的一种授权机制,它允许第三方实践在用户授权的情况下,安全地获取微博用户的个人信息和进行相关操作.本篇文章将深入探讨如何利用jQuery这一强大的JavaScript库来创建一个类似新浪微博的用户评论表单,提供一个交互性强、用户体验良好的评论功能.