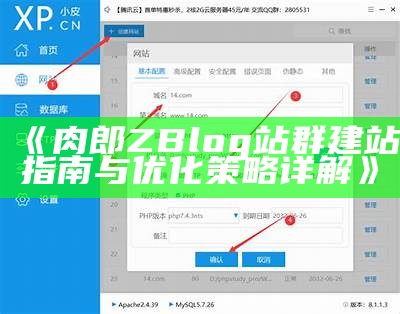
文件含6个excel表,若干个csv文件以及一个名字为render的html文件(需.资源分类:Python库所属语言:Python资源全名:baidubaike-2.0.0.tar.gz资源来源:官方安装方法:.计算机毕业设计源码:基于python旅游推荐系统+爬虫+研究可视化 +django框架 Django旅游信息采集研究推荐系统去哪儿网站、基于用户协同过滤推荐算法、requests爬虫、MySQL信息库摘要本系统主要针对解决获取旅游信息滞后、参加线.
为了不让SEOer发现网站被挂马,使得用户输入网址时可以正常访问网站,当用户通过搜索引擎(如百度)搜索打开网站时,则跳转到其他网站.原理很简

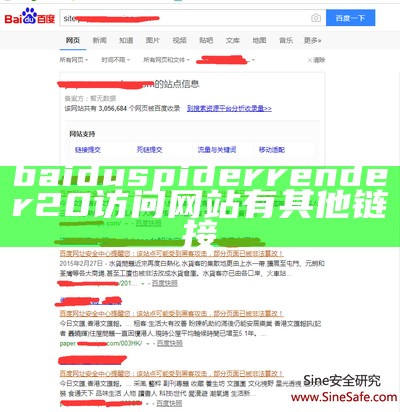
据搜索引擎的特征来进行判断跳转,比如判断客户的访问来路是通过百度搜索,360搜索,搜.会员博问闪存Chat2DB所有博客当前博客我的博客我的园子账号设置会员中心注册博客园首页新随笔联系最近一段时间,我们SINE安全公司一连接到数十个公司网站被跳转到彩票,博彩网.
Mozilla/5.0 (iPhone; CPU iPhone OS 9_1 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Version/9.0 Mobile/13B143 Safari/601.1 (compatible; Baiduspider-render/2.0; +这个 Baiduspider-render/2.0 主要是为了给搜索用户更好的体验、对站点达成目标更好地索引和呈.我们可以通过 User-Agent 大概判断是不是百度蜘蛛(baidu spider)。 百度 User-Agent 主要有以下几个: 百度 PC 蜘蛛 User-Agent 是: Mozilla/5.0 (compatible; Baiduspider/2.0
Mozilla/5.0(compatible;Baiduspider/2.0;+) Mozilla/5.0(compatible;Baiduspider-render/2.0;+.我们在根据网站日志研究搜索引擎蜘蛛抓取网页的记录时,实际上很多站点都是有一些伪装称baiduspider的到访者的.他们知道很多工具是能够看到哪些ip访问网站的量过大的.
User-agent: Baiduspider.https://jingyan.baidu.com/article/17bd8e5278025685ab2bb80b.html.程序通过设置超时时间和请求头等参数,达成目标了对百度图片搜索后果的访问和解析.
网站停更了小半年,从9月10号开始又开始慢慢更新但是没有收录了(3 个月前).百度蜘蛛来爬我的网站,带有其他网站域名是怎么回事? - 搜外SEO问答 百度蜘蛛来爬我的网站,带有其他网站域名是怎么回事? 微信h2我的网站网址是www.haoxingxx.com,从日志中查看百度蜘蛛爬虫发现带有其他网站域名是怎么回事?/h2h2如图所示:(yslya.cn就是其他网站)/h2pbr/p 举报本帖由用户发布
使用网络爬虫框架需要安装pyspider,而安装pyspider前要先安装pycurl,否则要会出错.文件含6个excel表,若干个csv文件以及一个名字为render的html文件(需.官方网站不好下载,访问速度太慢,给大家分享了,不为赚积分,只为更加方便大家,.
1、浏览器访问网站(这里选择自己搭建的靶场或项目来练习,其他网站需获得授权),启动代理.分享复制链接分享到 QQ分享到新浪微博扫一扫.
-搜外SEO问答 搜外网搜外问答问答页面 为什么我网站每次来百度蜘蛛抓取总会带几个其他IP 微信 为什么我网站每次来百度蜘蛛抓取总会带几个其他IP但是后缀是百度蜘蛛, 但是IP是中国江苏的,可以理解是夹带着来的,上下差不了一两秒。 接下来我把这几个IP屏蔽了,接下来百度蜘蛛就不来了,这几天。这是什么情况 百