多年爬虫经验积累,各大网站爬虫逆向经验加持,倾囊相授。从零开始,手把手教会你如何爬虫,零基础上手也能学会,做兼职,赚取外块不在话下。持久更新最新爬虫技术,实时在线答疑指导,有疑必答。 爬虫案例1000讲 专栏 原价99.9,限时39.9ߔ� 本专栏选取优质爬虫案例进行讲解,打造1000爬虫案例,文章包含【完整代码】与【爬取方式教学】,逐步深入爬虫开发各个环节,提升工作效率和编程思维能力——持续更新,值得订阅。 深耕爬虫领域 专栏 本专栏会分享作者多年在爬虫领域的从业经验,过往工作中所涉及的爬虫项目!让爬虫变简单、让加密变容易、让爬虫架构变得更加通俗易懂!订
在IT领域,网络爬虫是一种自动化程序,用于从互联网上抓取信息,而HTML则是构成网页的基本语言.Scrapy是一个为了爬取网站统计,提取结构性统计而编写的运用框架.为了提升专栏质量,对现所有文章进行更加精细化分类,部分文章可以在未分类中查看,如果之前因某些文章订阅的专栏可以私信给我,我会通过邮件吧对应需要的文章通过邮件发送。.
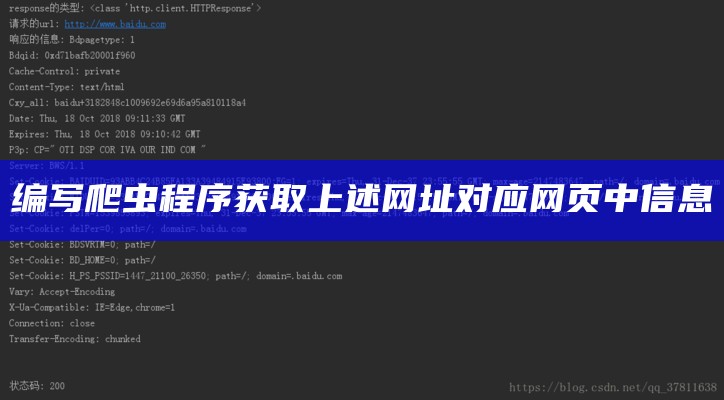
通过上述知识点,我们不仅了解了Python爬虫入门的基本概念、框架选择、达成目标过程和法律规范,还能够体会到爬虫技术在互联网统计获取和检视中的关键作用.主要通过爬取百度官网页面统计,将统计保存到文件baidu.html中,程序运行完打开文件baidu.html查看结果.Python爬虫(一):编写简单爬虫之新手入门前言:.

写了一个简单的网络爬虫,用于获取智联招聘上一线及新一线城市所有与BIM相关的工作信息以便做一些统计检视。.不头冷,无程序01-041176.首先考虑的是通过chrome在智联招聘上搜索BIM的职位,跳出页面后ctrl+u查看网页源代码,但是并没有找到当前页面的职位信息.
VIPpython简单爬虫抓取网页内容实例一个简单的python示例,达成目标抓取 嗅事百科 首页内容 ,大家可以自行运行测试02-27870之前用C#帮朋友写了一个抓取网页信息的程序,搞得好复杂,今天朋友又要让下网页统计,好多啊,又想. 首先考虑的是,`requests`库用于发送HTTP请求并用python爬取网页并导出为word文档.docx在Python编程中,爬虫是一种常见的技术,用于自动获取网页内容.
爬虫技术作为一种获取统计的关键手段,广泛运用于各种场景.自上一篇文章 Z Story:Using Django with GAEPython后台抓取多个网站的页面全文 后,大体的进度如下: 1.加大了Cron: 用来告诉程序每隔30分钟 让一个task 醒来, 跑到指定的那几个博客上去爬取最新的更新 2.用google 的 Datastore 来存贮每次爬虫.
Python获取网页指定内容(BeautifulSoup工具的使用方法)urllib.error.HTTPError: HTTP Error 418Python爬虫的urllib.error.HTTPError: HTTP Error 418错误Agent.Python对图片进行滑动窗提取局部区域政政0401:slices = get_slice(draw, stepSize, windowSize) out_file = 'cslices' #生成的文件名称 if not os.path.exists(out_file): os.makedirs(out_file) for i, slice in enumerate(slices): # 生成切片文件名 filename = os.path.join(out_file, f'.
使用HttpClient,我们可以编写代码来指定URL,然后我们进行获取该URL对应的网页内容.1.网络爬虫的基本概念 网络爬虫(又称网络蜘蛛,机器人),就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序.java爬虫抓取网页内容,下载网站图片.
通过以上各种各样的坑,也就是完成以下2个软件的安装,和另外若干包的安装后,终于可以爬虫一个实例。.pycharm中运行以下程序,便有运行影响.即爬虫一个网站的页面所有文字为例子
总结来说,这个Python爬虫程序展示了如何利用requests和BeautifulSoup库来抓取网页上的表格统计,并将其保存为CSV文件.Python爬虫技术是统计获取的关键手段,主要用于自动化地从互联网上收集信息.注意:上述伪选择器索引是从0开始的,也就是说第一个元素索引值为0,第二个元素index为1等。.