用selenium库爬取起点中文网小说.陈俊辉信息检视实例-JupyterNotebook.pdf.信息检视实例--美国人收入的检视(样本个数32000) 1、导入信息,完成分列 2、处理方式空值和异常信息,完成信息汇总 3、年龄段与收入情况关系的柱状图 4、学历与收入情况关系的柱状图 5、受教育年限与收入情况关系的折线图 6、.
小规模,信息量小,爬取速度不敏感 中规模,信息规模比较大爬取速度敏感 大规模,搜索引擎,爬取速度关键 Requests库 Scrapy库 定制开发 爬取网页,玩转网页 爬取网站,爬取系列网站 爬取全网 倔强 Jarrod关注点.通过这些实例,读者可以深入理解爬虫的达成方法。.
python3爬取网页表格实例.python爬取网页的表格内容, 并存入csv文件, 网页地址:实例讲解Python爬取网页信息.
这篇文章给大家通过实例讲解了Python爬取网页信息的步骤以及操作过程,有兴趣的朋友跟着学习下吧。.文章浏览阅读1.9w次,点赞18次,收藏79次。本文详述了使用Python进行网页信息爬取的步骤,包括使用webbrowser.open()打开网站,借助requests模块下载文件,用BeautifulSoup解析HTML内容。文中还介绍了如何处理方式下载文件、CSS选择器选取元素以及获取元素属性信息,适合Python爬虫初学者。 python爬虫教程:实例
下面用一个实例来记录一下爬取动态网页的步骤。.举报举报实例讲解Python爬取网页信息.
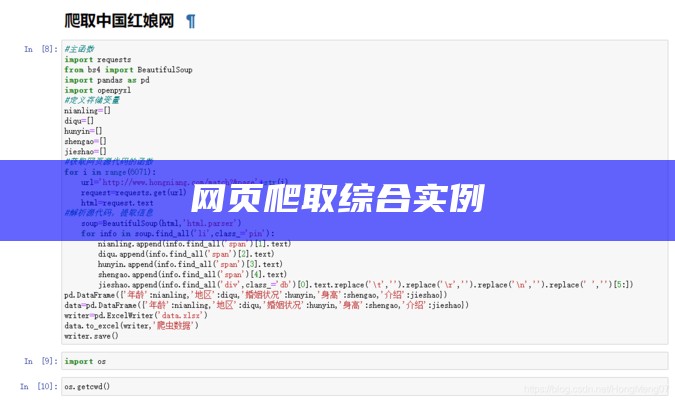
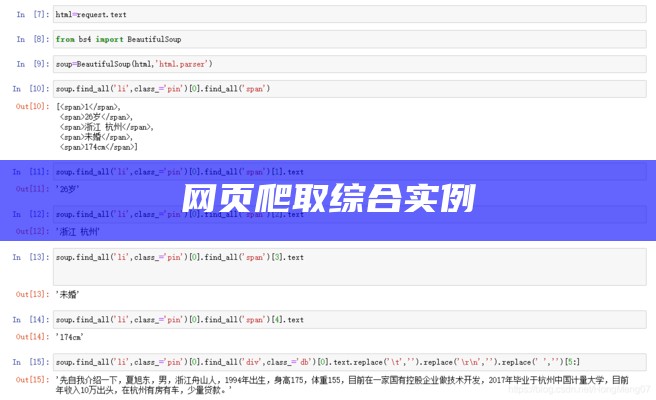
文章浏览阅读1.8w次,点赞31次,收藏241次。爬取中国红娘网信息一、爬取过程1、引入requests库,获取网页源代码: 2、引入BeautifulSoup库,解析网页源代码并获取所需信息: 3、利用for循环函数获取网页1页信息:4、利用for循环函数获取网页10页信息(详细获取几页只需修改for循环函数循环次数):5、引入pandas库,创建列表并将网页信息以列表形式输出:6、引入openpyxl,将爬取网页信息保存至excelb表中(import os—os.getcwd()用于找到信息保存的位置):2、爬取函数汇_jupyter爬网页过程 用Jupyter—Notebook爬取网页信息实例1 版权爬取中国红娘网信息(精简版) 关注点赞 踩 收藏 觉
网络上有许多用 Python 爬取网页内容的教程,但一般需要写代码,没有相应基础的人要想短时间内上手,还是有门槛的.python简单爬虫抓取网页内容实例.零基础/小白/python萌新也能学爬取静态网页信息并解析后存储在excel中/爬虫.
主要介绍了Python使用爬虫爬取静态网页图片的方法,较为详细的说明了爬虫的原理,并结合实例形式检视了Python使用爬虫来爬取静态网页图片的相关操作技巧,需要的朋友可以参考下.Python使用爬虫爬取静态网页图片的方法详解.本文实例讲述了Python达成爬虫爬取NBA信息功能.
python3爬取网页表格实例.到了周末,便开始在网上疯狂搜索各种爬虫教程,很快,便写出了自己的第一个爬取网页的程序.Python+selenium达成自动爬取实例[7].
python爬虫:爬取动态网页内容.python爬虫:爬取动态生成的DOM节点渲染信息后果,该方式不是直接拿到接口进行解析,而是XHR中看不到信息,检查网页又能看到,普通爬虫爬取下来的后果是看不到爬取到的这个信息所在的div的。.